最近在学习 MySQL 查询优化的知识,正在阅读简朝阳编写的《MySQL性能调优与架构设计》,受益良多。
作者先介绍了 MySQL 的基础知识,比如 MySQL 的架构组成,有哪些存储引擎,不同存储引擎的数据表会有什么样的物理文件,它的逻辑模块组成有哪些等等。
接着作者就谈到了 MySQL 的性能优化,讨论了影响 MySQL 性能的相关因素有哪些,MySQL 中的锁定机制,MySQL 的索引类型,一些类型的查询的优化技巧及原则等等。
这本书还没看完,还在继续学习中 ...
昨天同事说有个查询语句很慢,查询一次要 40 多秒,问我有没有时间帮看看怎么优化。我当然乐意了,正好可以用来练练手,看学习到的知识有没有用。经过不断的优化之后,那条语句被我优化到了 0.03 秒的速度,速度提高了几个数量级。
这更加坚定了我继续学习 MySQL 查询优化的信心!
以下是记录整个语句优化的过程:
- 刚开始的慢查询
SELECT
b.headimgurl
FROM
bdtt_view_share_log_11 AS a
LEFT JOIN
mdrt_weixin_mp_user AS b ON a.unionid = b.unionid
WHERE
a.author_unionid = 'opBomw1reHNZhG_X2c4a1W2y4N1o'
AND a.use_type = 0
AND a.type = 3
GROUP BY a.unionid
ORDER BY RAND()
LIMIT 8;
这条查询语句涉及到两张表,bdtt_view_share_log_11 和 mdrt_weixin_mp_user ,它们的数据量分别是 250 w 和 2100 w 的级别;字段 unionid 和 author_unionid 都建有索引。
刚拿到这条查询语句,第一感觉就是有 rand() 随机排序,还有对 unionid 进行分组操作。rand() 随机排序是公认的比较难以优化的,它是无法使用索引的。group by 如果能够用得上索引的话,情况并不会太糟糕。还有一个 LEFT JOIN 关联查询,这个也是可能会出现性能问题的点,但还是会有一定的优化套路可用的。
以上是一个主观的判断,实际情况是什么样的,得看看大名鼎鼎的 EXPLAIN。
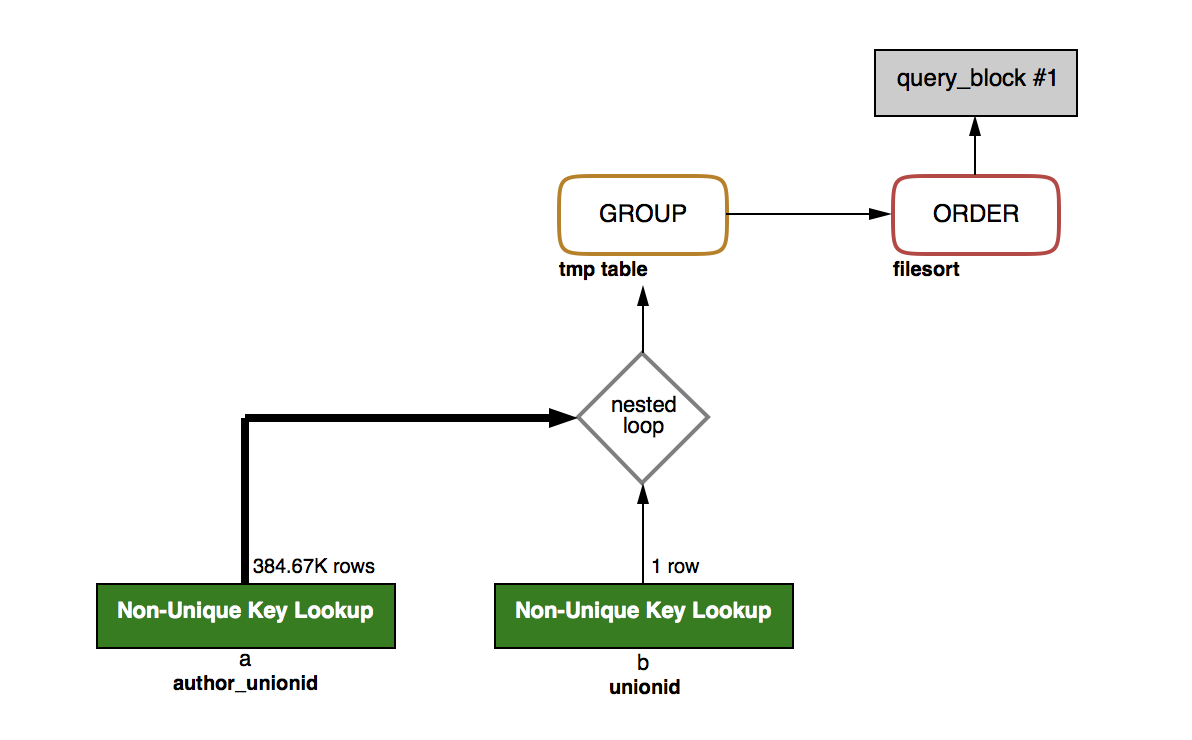
图为 MySQL 查询计划的可视化图
从图中可以看出,确实和刚开始的预感一样,性能的瓶颈在于 rand() 的随机排序。MySQL 需要对 38 w 的数据进行随机排序,有多慢可想而知了!这里有一个可以优化的地方,根据小结果集驱动大结果集的原则,我们可以先将 a 表使用条件进行过滤之后,在将其结果集与 b 表进行 JOIN。
- 根据小结果集驱动大结果集的原则优化
SELECT
b.headimgurl
FROM
(SELECT
unionid
FROM
bdtt_view_share_log_11
WHERE
author_unionid = 'opBomw1reHNZhG_X2c4a1W2y4N1o'
AND use_type = 0
AND type = 3
GROUP BY unionid
ORDER BY RAND()
LIMIT 8) a
LEFT JOIN
mdrt_weixin_mp_user AS b ON a.unionid = b.unionid
LIMIT 8;
经过这样子的优化之后,这条语句的查询时间已经减少到 1 秒多了,它的执行计划图如下:
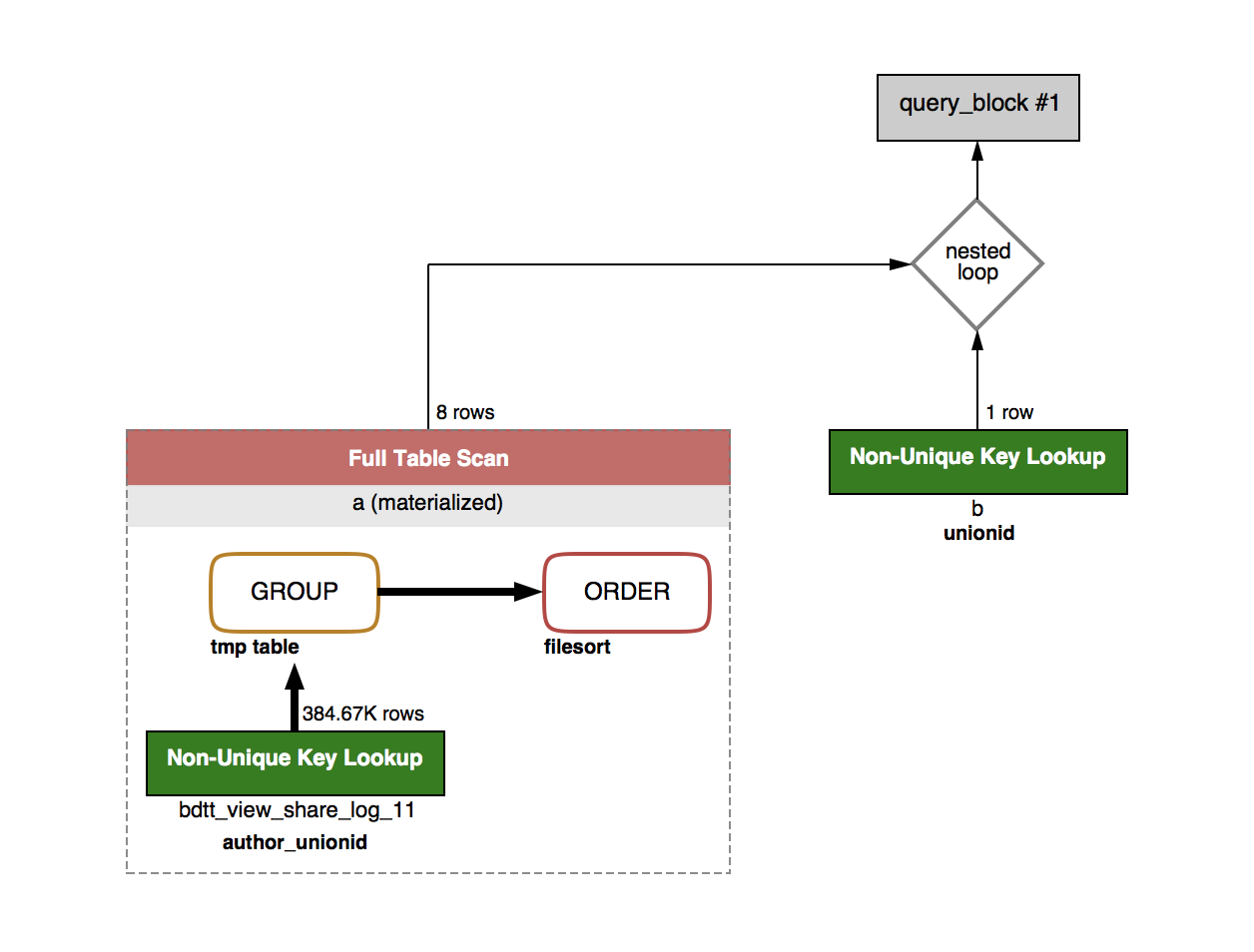
可以从图中看出,经过优化之后,与 b 进行关联查询的结果集只有 8 条数据而已了,而不是刚开始的 38 w 条数据进行关联,这使得查询时间大大的降低了。
可是,这查询还需要 1 秒多时间呢,这在生产环境中也还是不能忍受的啊!
现在的关键点还是在于 rand() 这个随机排序这里。在网上查找相关的解决方案,大部分的都是先在程序中随机生成必要的主键,然后根据主键就能找到随机的记录了;要么就是生成一个小于最大值数,然后从那个数开始取连续的几条数据。这些在这条查询中都不管用!
后来我就取了一个折中的方案,不从全局中去随机数据,只是从部分结果集中取随机的 8 条数据,这样参与随机排序的数据就可以控制在一定范围内了。况且,这里的随机的结果只是给用户一个不一样的感觉而已,所以这样子做并不会有什么多大的不妥。
还有一点,这里的 group by 可以使用 distinct 来取代,因为 group by 还会多一个排序的操作,而我们不需要排序。
- 折中的随机排序方案
SELECT DISTINCT
b.headimgurl
FROM
(SELECT DISTINCT
unionid
FROM
bdtt_view_share_log_11
WHERE
author_unionid = 'opBomw1reHNZhG_X2c4a1W2y4N1o'
AND use_type = 0
AND type = 3
LIMIT 100) a
LEFT JOIN
mdrt_weixin_mp_user AS b ON a.unionid = b.unionid
ORDER BY RAND()
LIMIT 8;
这样已经优化到 0.03 秒了。以下是执行计划图:
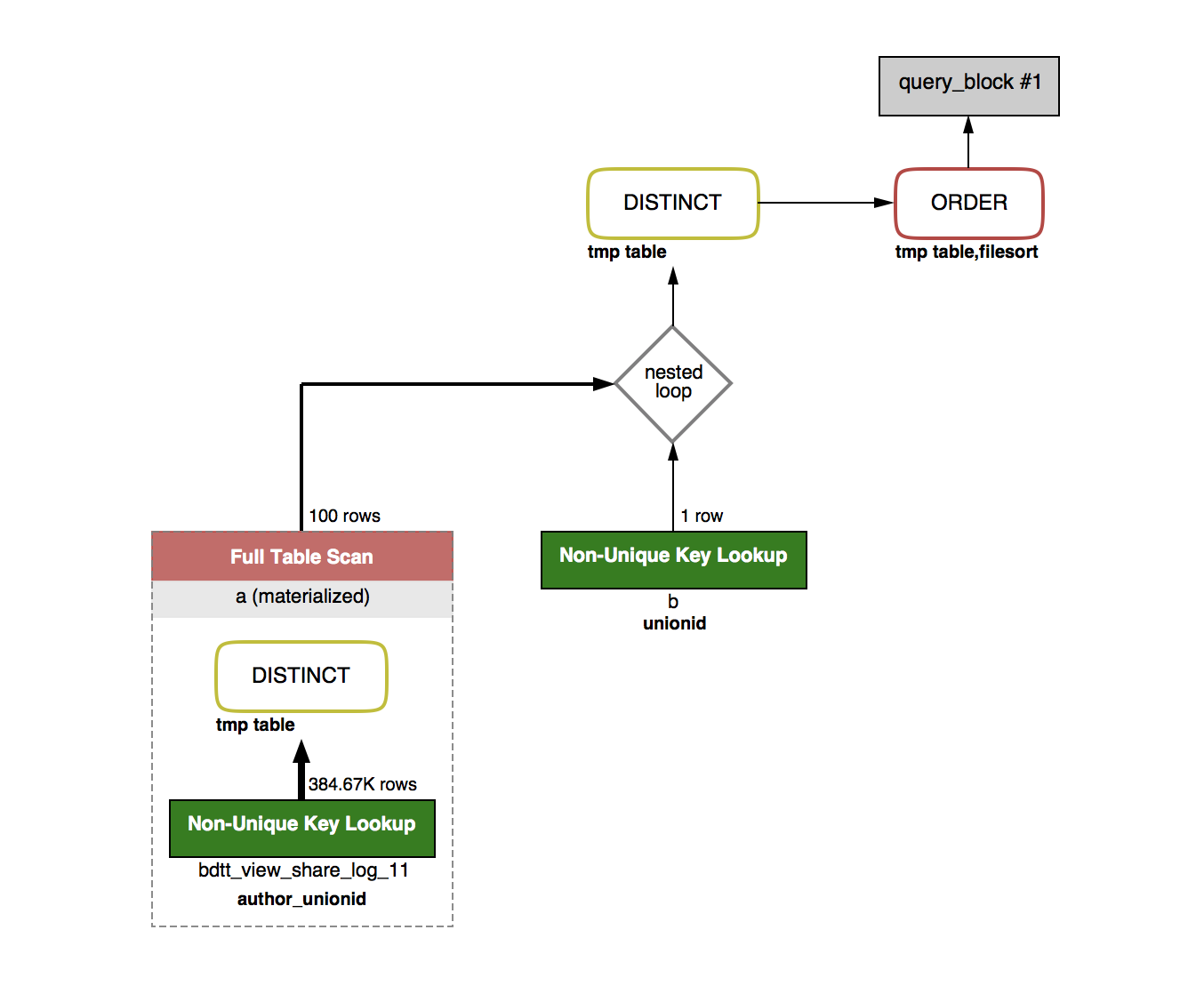
可以看到,最后参与随机排序的结果集也就百来条而已了,MySQL 服务器处理这点数据应该还是挺快的吧。
到这里,这条慢查询的优化就暂时告一段落了。
最后,继续学习,优化永无止境!!
本文作者: chenishr
本文标题:《记一次 MySQL 查询优化》
本文地址: http://blog.chenishr.com/?p=708
©版权所有,除非注明, 永在路上文章均为原创,转载请以链接形式注明出处和作者细信息。
牛逼啊。